
声掩蔽技术浅析
 打印
打印
【摘 要】 保密会议室等重要场所围护结构的缺陷会导致声音泄漏隐患。声掩蔽技术通过产生特定的声音,对泄漏的语音进行干扰,是保障声音信息安全的重要手段。本文从关键技术及评价方法等方面对声掩蔽技术进行了分析,指出目前存在的问题,并对未来发展提出了建议,为声掩蔽系统的研发、测试、使用及维护提供参考。
【关键词】 声掩蔽?声音泄漏?声音信息安全
1 引言
随着信息技术的发展,利用高灵敏度拾音器、拾振器等技术手段及高效的语音复原方法,窃听者能够在室外以非入侵方式窃取室内的语音,给这些场所的声音信息安全带来严峻挑战。
根据门、窗、墙体、管道等建筑围护结构和设施的声学特性,室内语音可经由空气传声和固体振动传声等渠道泄漏至室外,泄漏程度与室内声源声压及其声场分布、围护结构隔声、室外噪声水平、安全距离等因素有关。对声音信息泄漏的防护可分为2种途径:一种是屏蔽,即采用吸声、隔声、减振等措施将室内声音阻挡在场所边界内或使泄漏的声音充分衰减,但需要对建筑围护结构和内部管道等设施进行改造,成本高昂,维护升级困难,灵活性差;另一种是干扰,即向声音泄漏路径或窃听风险位置施加其他声音,以干扰接收者对泄漏语音的理解和恢复,这一技术称为声掩蔽(sound masking)。该方法可以弥补场所的声学缺陷,具有使用灵活、成本低、可重用等优点,成为保障声音信息安全的重要技术手段。
2 声掩蔽技术现状
声掩蔽技术是基于人耳的听觉掩蔽效应提出的,即一个声音的存在使另一个声音的听觉阈值提高而不易被听到的现象。利用掩蔽效应,通过向目标区域施加特定的掩蔽声,可以掩盖和干扰泄漏的语音,保护语音信息的安全。按照防范对象,声掩蔽技术可分为2种应用领域:一种是针对无意听者的语音隐私保护,常见于开放式办公室、医院、银行、话务中心等人员密集但隔声不佳的场所,其目的在于避免谈话被他人听到或对他人造成干扰;另一种是针对恶意听者的语音信息保护,常用于产生敏感语音信息的场所。二者在应用场景及技术路线上有很大不同。隐私保护主要针对空气渠道泄漏的声音和无意收听,通常只需使用噪声、流水声、音乐等较为舒缓的声音作为掩蔽声,以提高背景声压水平,技术上主要关注掩蔽效果和舒适性。而信息保护用途针对的是潜在的恶意窃听者,其可能使用各种先进的拾音、拾振装置及语音复原技术进行窃听,因而对掩蔽声的掩蔽能力有更高的要求;除了对空气声泄漏的防护,还需防范振动声泄漏隐患;同时,声掩蔽系统的防破解、防破坏等安全问题也需要考虑。
国际上对声掩蔽技术的研究起步较早,美国、澳大利亚和欧洲一些国家都研制出了较为成熟的声掩蔽产品。国外也出台了相关标准规范,如美国情报部门在2002年制定了专门规范,对敏感信息隔离设施的隔声及声掩蔽等声学防护措施提出了要求;美国军方也颁布了相关标准对军用敏感信息隔离设施提出了声音防护要求。国外研制的声掩蔽产品众多,但可获得的技术资料和产品大多针对隐私保护等普通应用,且汉语与英语有较大区别,国外技术未必适合汉语特征。因此,研发安全可控的声掩蔽技术和产品势在必行。我国的声掩蔽技术、产品和规范目前尚不完善,声掩蔽系统的有效性和安全性尚有待验证。
3 声掩蔽系统的关键技术
典型的声掩蔽系统通常由掩蔽声发生器和输出终端组成。其中,掩蔽声发生器产生掩蔽信号,并对其强度和频谱等特征进行调节;输出终端通过扬声器或激振器等换能装置将掩蔽声的电信号转换为空气声或振动声信号。以下对声掩蔽系统的关键技术进行分析。
3.1 掩蔽声源的设计
足够强的掩蔽声可以掩盖泄漏的语音,但同时会对附近人员产生干扰,影响其听觉舒适度。因此,掩蔽声的掩蔽效果和舒适性通常是矛盾的。掩蔽声源的设计目标是设计高效、舒适的掩蔽信号,以更小的掩蔽强度达到更优的掩蔽效果。常见的掩蔽声源可以归纳为以下3类。
3.1.1噪声
噪声是自然界中最常见的干扰声源,因此常用作掩蔽声,如白噪声、粉噪声、空调噪声、群口噪声(多人同时说话的噪声,也称babble噪声)等。但噪声与被掩蔽语音的相关性低,掩蔽效率不高。对常见噪声掩蔽能力的实验表明,语音信号与掩蔽声的功率比(信掩比)在-15dB以下时,被掩蔽的语音基本不可懂,0dB以上基本完全可懂,在-10~0dB时掩蔽效果与掩蔽声源关系密切,常见噪声中babble噪声最优、粉噪声次之、白噪声最差。这是因为babble噪声由多人语音构成,与目标语音具备一定的相似性,同其他噪声相比有更好的掩蔽能力。例如,信掩比在-12dB时babble噪声可使单词可懂度下降到10%左右,而相同条件下的空调噪声掩蔽后的单词可懂度接近60%。但babble噪声随时间波动更剧烈,且包含可被理解的语义信息,因此,同白噪声等平稳噪声相比,相同声压下的舒适性较差。
3.1.2自然声
自然界产生的声音(如瀑布、降雨、溪流、鸟鸣、风声等)通常具有很好的听觉舒适度,对人的消极影响小,因此常用于声景观和声掩蔽系统中。与噪声相同,自然声也存在掩蔽能力不足的缺陷。实验表明,在各种自然声中流水声表现出较高的掩蔽效率和舒适性。
3.1.3类语音
声音的掩蔽效应可以分为能量掩蔽和信息掩蔽,前者通过掩蔽声在时间和频率上的能量重叠对目标语音形成干扰,而后者产生的机理尚不十分明确,通常被认为是掩蔽声提高了听觉中枢系统的加工负荷,使其处理目标语音时资源不足。同能量掩蔽相比,信息掩蔽利用了人脑更深层次的信息处理机制,可能以更低的能量实现更高效的掩蔽。研究表明,提高掩蔽声和目标语音的相似性是产生信息掩蔽的可能途径,特别是认知、语义等特征上的相似性会极大提高听者的区分难度。
类语音(speech-like noise)是一种具备语音特征但又没有明确语义的声音信号,即听上去有人说话但又不知所云。类语音在心理声学特征上与被掩蔽语音接近,因此掩蔽效率比噪声和自然声更高。同时,语义的缺失使其对周围人注意力的影响减小,有利于改善掩蔽声的舒适性。一种实现策略是通过目标语音来构建掩蔽声,以获得二者最佳的相似性。例如,将实时采集的目标语音分段并逐段进行时间反转可破坏其语义信息但保留其声学特征,因而成为构造类语音掩蔽声的一种有效方法,即时间反转法。研究表明,与空调噪声、babble噪声等掩蔽声源相比,时间反转类语音具有最强的掩蔽能力,在-12dB信掩比下句子可懂度几乎为0。但同babble噪声类似,其舒适性不如平稳噪声和自然声。此外,需要特别注意的是,尽管时间反转类语音生成方法可以对帧长等参数进行保护,但其声音信息完全来自目标语音,一旦反转规则被破解将完全丧失掩蔽能力,因此设计中需要更充分地考虑算法的安全性。
除上述3类声源外,音乐等类型的声音也可用作掩蔽声。不同类型的掩蔽声源在掩蔽效率、舒适性及安全性方面各有不同,混合使用则有望取长补短。例如,可以用平稳噪声进行基础的能量掩蔽,用类语音实现高效的信息掩蔽,用自然声或音乐改善舒适性,同时复杂的掩蔽声特征也提高了窃听者还原目标语音的难度。但可用于掩蔽的声源众多,混合方式及各声源的比例不胜枚举,如何设计出更高效、更安全、更舒适的掩蔽声仍需进一步研究。
3.2 掩蔽声的调节
声掩蔽系统的使用场景不同于传统的扩声系统,对声源进行高保真的声音重放不是主要目的。相反,若根据掩蔽声源、目标语音及现场声学环境的特征对掩蔽声进行调节,则可能改善系统的性能。例如,针对噪声、自然声等作为掩蔽声源与目标语音相似度不足的问题,可以通过滤波、均衡等处理使其具备与语音相近的频谱,以提高掩蔽效率。更进一步地,由于建筑围护结构的隔声在不同频率处不同,泄漏的语音与室内语音在频谱上存在较大差异,若将目标语音与围护结构隔声等特征作为掩蔽声频谱调节的依据,可产生更高效、更精细的掩蔽声。针对类语音等掩蔽声源与目标语音特征相似而舒适性不高的问题,向其中适当增加混响可以在保持掩蔽效果的同时提高舒适性。根据目标语音声压的变化自适应地调节掩蔽声的声压,可以获得更为稳定的掩蔽效果。此外,对掩蔽声源进行随机处理可以扩大掩蔽声的样本空间,提高其被破解或预测的难度,增加系统的安全性。
3.3 掩蔽声的输出
针对需要防护的声音泄漏渠道,掩蔽声的输出分为空气声和振动声(或固体声)2种类型。
3.3.1空气声掩蔽
由扬声器作为输出换能器,对经由空气传播的声音泄漏进行防护。传统的以隐私保护为目的的声掩蔽系统大多为此种类型,通常在围护结构周边存在声音泄漏隐患的空间内使用,如走廊、吊顶、通风管道等,特别是走廊内的门、窗等薄弱区域。扬声器的部署位置和密度应综合考虑掩蔽声的空间衰减、扬声器的指向性、背景噪声水平、室内声源位置、声音泄漏位置和泄漏程度等因素,使掩蔽声的声场分布与声音泄漏的分布相匹配。
3.3.2振动声掩蔽
由激振器作为输出换能器,产生振动信号,对经由固体振动传播的声音泄漏进行防护。室内语音将导致墙体、门、窗、管道等固体结构的微弱振动,由于固体中的声波衰减慢、传播距离远,而人耳又不易察觉,故振动成为广泛存在但又容易被忽视的声音泄漏渠道,也是极易被利用的泄密隐患。例如,窗户的振动可能被激光拾振器、指向性传声器等装置在远距离外探测到,墙体的振动可能被埋置的拾振器或光纤传声器采集,管道的振动可能被远端的拾振器拾取。虽然空气声掩蔽装置产生的声音可以在围护结构上形成振动干扰,但实验表明,正常声压下空气声掩蔽无法掩盖泄漏的振动声。因此,在窗户、门、墙壁、管道壁等振动声泄漏的高风险区域应施加振动声掩蔽,并结合围护结构的构造、室内声源分布、受控区域分布及安全距离等因素进行综合部署。
4 声掩蔽系统的评价
4.1 有效性
对同一种掩蔽声源,其输出功率越高,则掩蔽能力越强,但作为一种噪声源对周围人的影响也越大。因此,声掩蔽系统的有效性可用功率约束条件下的掩蔽效果来评价,或称为掩蔽效率。与用信噪比描述噪声的相对功率类似,掩蔽声的相对功率可用“信掩比”来描述,即被掩蔽语音信号与掩蔽声的功率之比,并用二者声压级(对空气声)或加速度级(对振动声)之差来测量和计算,也常称作目标-掩蔽比(Target-to-Masker Ratio,TMR)。掩蔽效果则用掩蔽后的语音质量、清晰度、可懂度等反映语音损伤程度的指标来评价,可以分为主观与客观2类。相同信掩比条件下,若掩蔽后的语音质量越差、越难听懂,则掩蔽效率越高。
4.1.1主观评价
通过听音实验,由受试者对掩蔽后的语音进行主观评价。常用方法包括以下2种。
(1)诊断押韵测试
国家标准GB/T 13504-2008提供了一种诊断押韵测试(Diagnostic Rhyme Test,DRT)方法,利用辅音对语音清晰度贡献大、对噪声敏感的特点,设计押韵的字表,由听音人记录听到的字,并统计正确识别的比例。标准将DRT得分分为5个等级,其中得分小于65%时,音质评价等级为不可接受。
(2)清晰度/可懂度测试
国家标准GB/T 15508-1995提供了一种语言清晰度测试(speech articulation test)方法,朗读或播放一组意义不连贯的音节,统计听音人正确记录的比例。可懂度测试可采用类似的方法,将语料更换为有意义的词或句,并统计听懂的比例。标准给出了音节清晰度与单词可懂度的统计关系,清晰度在40%以内时,单词可懂度近似等于音节清晰度的1.5倍。
4.1.2客观评价
主观实验耗时耗力,现场测试时部分位置可能难以到达。因此,可以借助一些与主观评价比较一致的客观评价方法,以简化测试过程。常用的客观评价方法主要有以下4种。
(1)清晰度指数
清晰度指数(Articulation Index,AI)由国家标准GB/T 15485-1995推荐,依据语音的各个频带对清晰度的贡献不同,测量各频带的信噪比并加权平均,得到0~1之间的AI值。标准还给出了AI与音节清晰度、单词可懂度和单句可懂度之间的统计关系。若要求单词可懂度不超过20%,则AI一般应不超过0.05,AI在该范围内近似等于单句可懂度。AI已被澳大利亚等国家采纳为语音私密度的评价标准,具备私密性的AI通常也不超过0.05。美国材料与试验协会标准ASTM E1130-16也提供了一种基于AI的开放空间内语音私密度的客观测量方法,支持对声掩蔽效果的评价。
(2)语音可懂度指数
语音可懂度指数(Speech Intelligibility Index,SII)在AI的基础上得到改进,并纳入美国标准ANSI S3.5-1997,取值也为0~1。具备私密性的SII通常不超过0.1。
(3)语音传输指数
语音传输指数(Speech Transmission Index, STI)是国家标准GB/T 12060.16-2017推荐的可懂度客观评价方法,能够反映包括噪声、混响、非线性失真及扩声系统在内的语音传输通道上各种干扰因素对可懂度的影响,取值范围0~1,最差等级为STI<0.36。具备私密性的STI一般不超过0.1。但该方法对起伏噪声敏感,对于类语音等具备波动性的非平稳掩蔽声,评价效果并不理想。
(4)语音质量感知评价
语音质量感知评价(Perceptual Evaluation of Speech Quality,PESQ)是国际电信联盟(ITU)建议的基于人类听觉模型的语音质量客观评价算法。其主要过程是将原始语音与处理或失真后的语音经过电平调整、滤波、时间对齐和听觉变换,提取其失真参数并映射成反映主观平均意见分(Mean Opinion Score,MOS)的客观分值,范围-0.5~4.5。MOS将语音质量分为5级,最差等级分值为1。研究表明,PESQ<2.3时,句子可懂度<50%;PESQ<2.0时,句子可懂度<20%。但语音可懂度与语音质量并不完全一致,特别是对低质量语音,即低质量并不一定意味着低可懂度。实验发现,极低质量的语音(如信噪比低于-5dB)PESQ得分与语音失真程度的关联不再显著。这是因为极低信噪比下语音被噪声淹没,PESQ算法对语音的分析和处理(如时间对齐)将出现较大误差,导致结果的不确定性加剧。
表1 声掩蔽有效性的评价指标
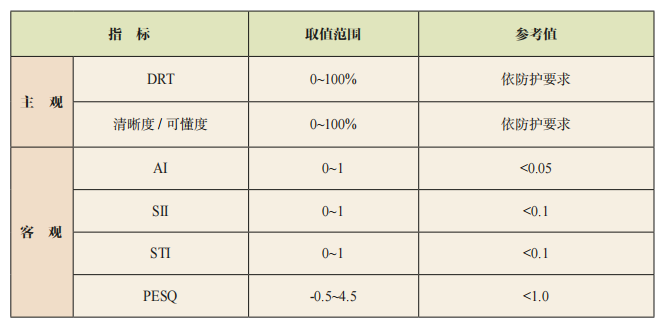
上述客观指标主要针对较高质量语音的评价进行设计,在评价声掩蔽系统或语音私密性方面存在局限性或未经验证;同时,能否用于评价振动声掩蔽的效果也有待研究。表1汇总了上述主、客观评价指标,其中参考值为依据现有文献给出的取值范围。需要说明的是,公开文献大多针对语音的隐私保护,并未考虑各种窃听手段的威胁,而安全防护应用通常有更高的要求,故参考值仅用于排除可能的语音泄漏隐患,不能作为评价保密性的依据。同时,对低质量语音的客观评价结果通常不稳定,可以允许一定的波动。
此外,美国材料与试验协会标准ASTM E2638-10提供了一种封闭房间语音私密性的客观测量方法,得到室外薄弱位置处的信噪比和语音隐私等级。但该标准只针对房间边界外发生的有意或无意窃听,不适用于借助电子或电声设备进行的恶意窃听。
4.2 安全性
声掩蔽系统的安全性尚无明确界定,本文从声掩蔽系统可能面临的攻击入手,对安全性进行分析。
4.2.1主动攻击安全防护
主动攻击通过对声掩蔽系统的入侵或破坏使其失去防护能力,如篡改掩蔽声源和系统设置、破坏或替换输出终端等。针对此类攻击,声掩蔽系统应具备权限管理策略,并设计声源、线路、终端等组件的异常监测及报警功能。
4.2.2被动攻击安全防护
被动攻击指通过对声音信号的采集和分析,从中去除或削弱掩蔽声并修复目标语音。被动攻击的手段多样、隐蔽且不断发展,要求声掩蔽系统在设计和使用过程中应更加谨慎,建议遵循以下原则。
(1)掩蔽声的产生应具备良好的随机性和非周期性。
(2)不同的设备应避免使用相同的掩蔽声源,并应经常更换。
(3)掩蔽声与目标语音的相关性应适度。二者特征越接近,越难被分离;但掩蔽声的生成不应过度使用目标语音的特征,特别是与语义、声纹等敏感信息相关的特征,以防止通过分析、破解掩蔽声而实施的信息窃取。
4.3 舒适性
掩蔽声的存在将对周围的人产生干扰,导致听觉舒适性降低。舒适性一般以人的主观感受来评价,如满意度、烦恼度、干扰度、侵入感、自然度、注意力集中度等。尽管在保密场合下,舒适性不是关注的重点,但良好的舒适性将提高参与者合理使用声掩蔽系统的积极性。因此,声掩蔽系统的设计和部署还应综合考虑掩蔽效果和舒适性的平衡问题。一般来说,相同声压条件下,平缓的声音比剧烈波动的声音更舒适,如平稳噪声比babble噪声舒适、流水声比雷声舒适;没有语义或听不懂的声音比能听懂的声音更舒适,如类语音和外语通常比母语更不容易分散人的注意力;此外,通过控制室内说话音量、设置安全距离、合理使用振动声掩蔽等都可以减小所需的掩蔽声声压,从而改善舒适性。
5 结语
在声音信息泄漏途径多而隐蔽、窃听手段日益先进的形势下,声掩蔽技术的应用将是一项复杂的系统工程。如何设计高效、安全、舒适的声掩蔽系统,以及如何准确、可靠地进行评价,都有待进一步研究。未来,随着我国对声音信息安全的日益重视和相关标准的出台,声掩蔽技术和产品将得到快速发展和广泛应用。
(原载于《保密科学技术》杂志2023年3月刊)
